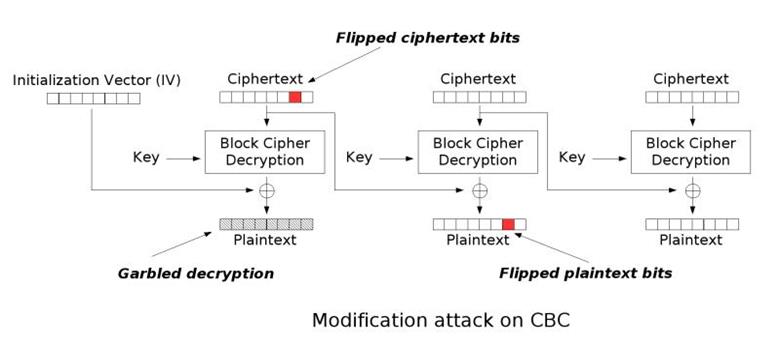
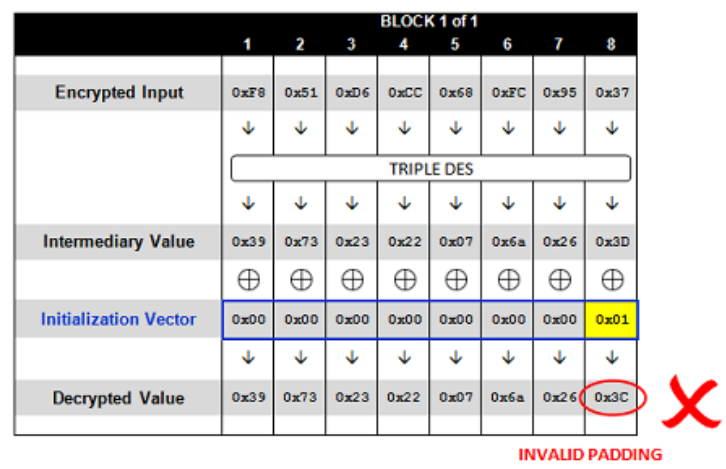
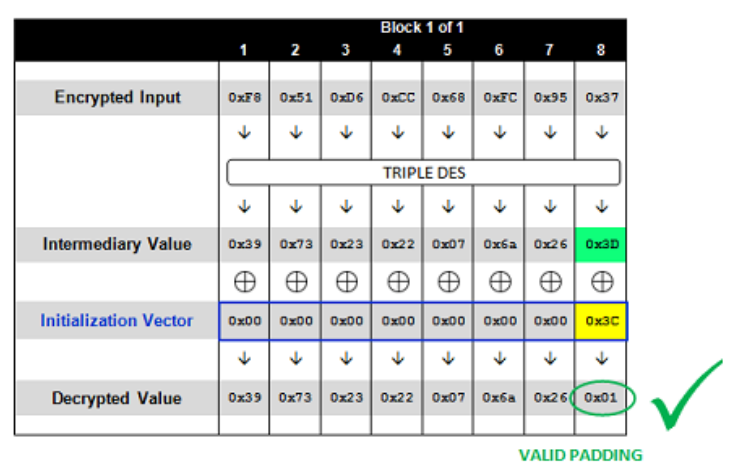
# unpadding and check padding characters defunpadding(msg): padding = msg[-1] if padding == 0: return msg, False for i inrange(padding): if (msg[-i-1] != padding): return msg, False return msg[:-padding], True
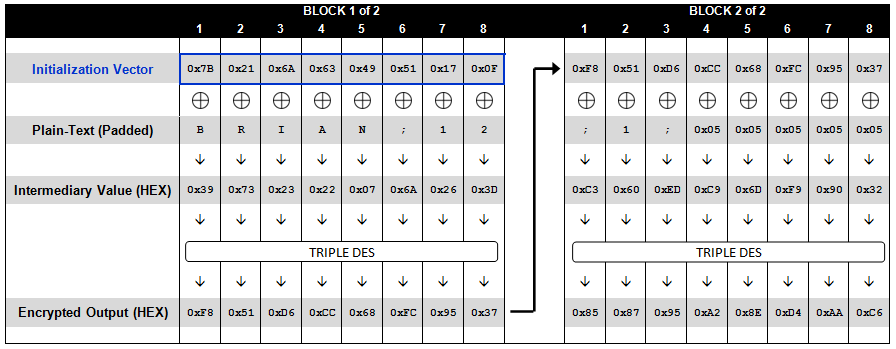
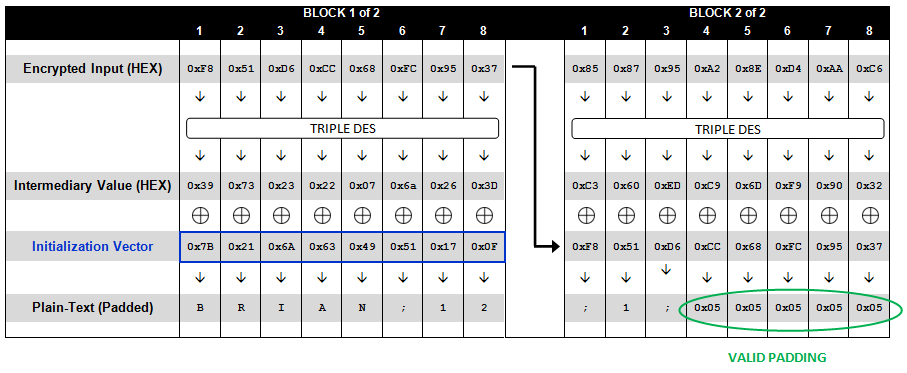
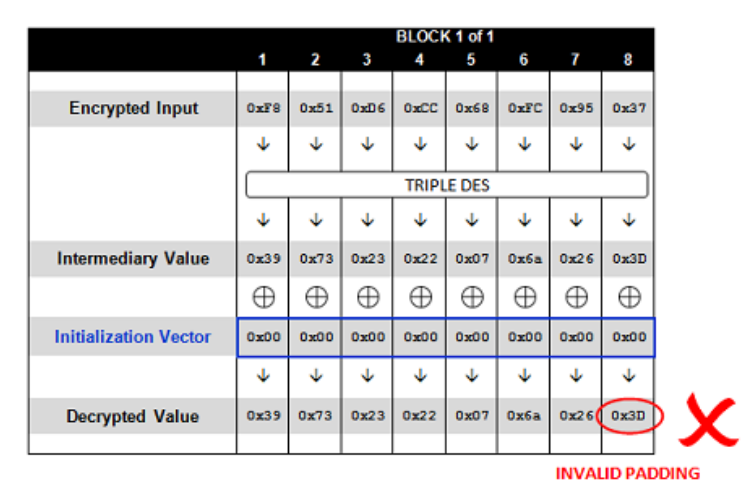
defpadding_oracle_attack(msg_enc, key, iv): middle = [0] * 16 for i in trange(16): my_iv = deepcopy(middle) if i != 0: my_iv[-i:] = xor(my_iv[-i:], [i+1]*i) print(my_iv) for j inrange(256): my_iv[-i-1] = j
msg_after_padding = AES_CBC_dec(msg_enc, key, bytes(my_iv)) flag = unpadding(msg_after_padding)[1] if flag == True: middle[-i-1] = j ^ (i+1) break
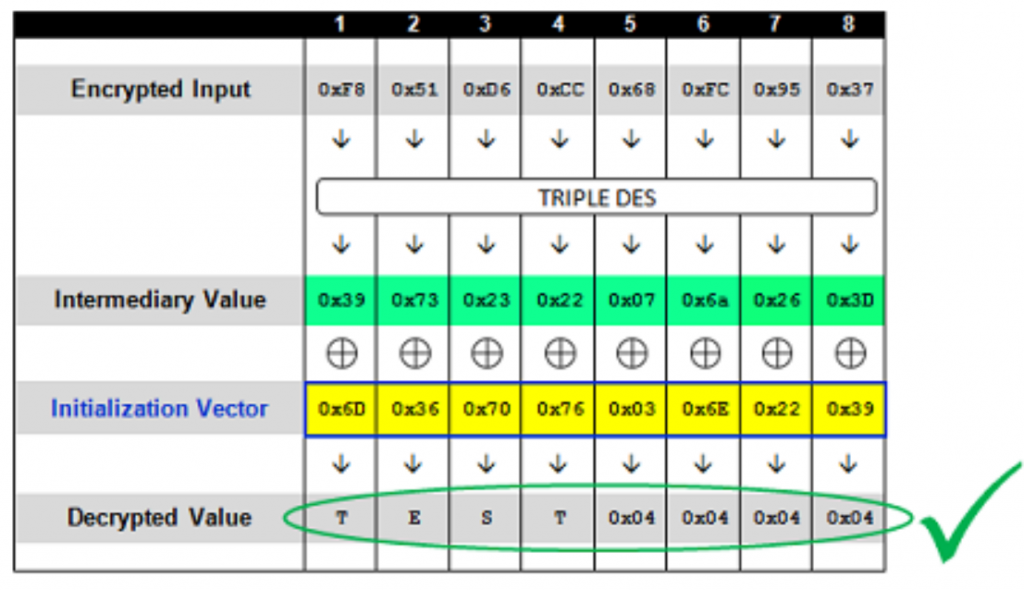
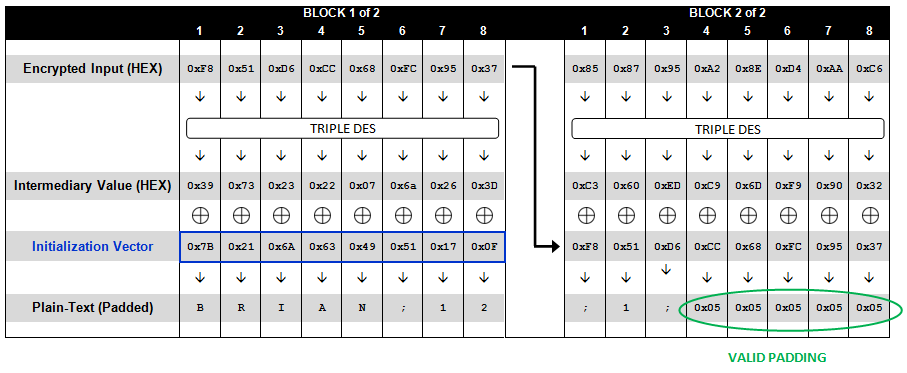
msg_after_padding = xor(middle, bytearray(iv)) print(msg_after_padding) msg, flag = unpadding(bytes(msg_after_padding)) if flag == False: returnNone return msg
msg = os.urandom(random.randint(1,15)) key = os.urandom(16) iv = os.urandom(16) print(msg)
defasserts(pt: bytes): num = pt[-1] iflen(pt) == 16: result = pt[::-1] count = 0 for i in result: if i == num: count += 1 else: break if count == num: returnTrue else: returnFalse else: returnFalse
defdecrypt(c): iv = c[:32] cipher = c[32:] plain_text = cbc_decrypt(binascii.unhexlify(cipher), binascii.unhexlify(iv)) if asserts(plain_text): returnTrue else: returnFalse
if hashlib.sha256((XXXX + random_str[4:].encode())).hexdigest() != str_sha256: returnFalse
returnTrue
defhandle(self): ifnotself.proof(): self.request.sendall(b'Error Hash!') return cipher = encrypt() self.request.sendall('Welcome to AES System, please choose the following options:\n1. encrypt the flag\n2. decrypt the flag\n'.encode()) n = 0 while n < 65536: options = self.request.recv(512).strip().decode() if options == '1': self.request.sendall(('This is your flag: %s\n' % cipher).encode()) elif options == '2': self.request.sendall('Please enter ciphertext:\n'.encode()) recv_cipher = self.request.recv(512).strip().decode() if decrypt(recv_cipher): self.request.sendall('True\n'.encode()) else: self.request.sendall('False\n'.encode()) else: self.request.sendall('Input wrong! Please re-enter\n'.encode()) n += 1 return
from pwn import * import itertools from copy import deepcopy from tqdm import trange from string import ascii_letters, digits import hashlib import binascii
# context.log_level = "debug" p = remote("127.0.0.1", 10010)
defget_proof(): p.recvuntil(b"SHA256(XXXX + ") last = p.recvuntil(b"):", drop=True) shav = p.recvline()[:-1] print(f"last = {last}") print(f"shav = {shav}") for cont in itertools.product(ascii_letters + digits, repeat=4): cont = ''.join(cont).encode() if hashlib.new("sha256", cont + last).hexdigest() == shav.decode(): print(cont) break p.sendlineafter(b"Give Me XXXX:\n", cont)
# unpadding and check padding characters defunpadding(msg): padding = msg[-1] if padding == 0: return msg, False for i inrange(padding): if (msg[-i-1] != padding): return msg, False return msg[:-padding], True
defpadding_oracle_attack(iv, c): solved_dec = [0] * 16 for i in trange(16): new_iv = deepcopy(solved_dec) if i != 0: new_iv[-i:] = xor(new_iv[-i:], [i+1]*i) for j inrange(256): new_iv[-i-1] = j
p.sendline(b"2") p.sendlineafter(b"Please enter ciphertext:\n", (bytes(new_iv).hex() + c.hex()).encode()) if p.recvline() != b"False\n": solved_dec[-i-1] = j ^ (i+1) break
msg_after_padding = xor(solved_dec, bytearray(iv)) print(msg_after_padding) msg, flag = unpadding(bytes(msg_after_padding)) if flag == False: returnNone return msg
get_proof()
p.sendlineafter(b"1. encrypt the flag\n2. decrypt the flag\n", b"1") iv_and_c = binascii.unhexlify(p.recvline().decode()[19:-1]) iv, c = iv_and_c[:16], iv_and_c[16:] print(f"iv = {iv}") print(f"c = {c}")
msg = padding_oracle_attack(iv, c) print(msg)
""" last = b'OfBypjLi4BizYvHW' shav = b'c0786d83da7177ab64ac113343ad157e4a7784998fb2be1ff84ab1e378499375' b'OTnk' iv = b'`\xb9\x9c\xa7K>SfC|\xabz\x8b*\x00`' c = b'#\xad\xfd\x84m\x16F\x17\xc3\xc9s\xce\x02\x86\x04\x88' 100%|██████████| 16/16 [00:00<00:00, 51.35it/s] b'Obflag{test}\x04\x04\x04\x04' b'Obflag{test}' """
#coding=utf-8 from pwn import * import base64, time, random, string from Crypto.Cipher import AES from Crypto.Hash import SHA256, MD5 #context.log_level = 'debug' if args['REMOTE']: p = remote('52.193.157.19', 9999) else: p = remote('127.0.0.1', 7777)
defstrxor(str1, str2): return''.join([chr(ord(c1) ^ ord(c2)) for c1, c2 inzip(str1, str2)])
defrecvmsg(): data = p.recvuntil("\n", drop=True) data = base64.b64decode(data) return data[:16], data[16:]
defgetmd5enc(i, cipher_token, cipher_welcome, iv): """return encrypt( md5( token[:i+1] ) )""" ## keep iv[7:] do not change, so decrypt msg[7:] won't change get_md5_iv = flipplain("token: ".ljust(16, '\x00'), "get-md5".ljust( 16, '\x00'), iv) payload = cipher_token ## calculate the proper last byte number last_byte_iv = flipplain( pad("Welcome!!"), "a" * 15 + chr(len(cipher_token) + 16 + 16 - (7 + i + 1)), iv) payload += last_byte_iv + cipher_welcome sendmsg(get_md5_iv, payload) return recvmsg()
defget_md5_token_indexi(iv_encrypt, cipher_welcome, cipher_token): md5_token_idxi = [] for i inrange(len(cipher_token) - 7): log.info("idx i: {}".format(i)) _, md5_indexi = getmd5enc(i, cipher_token, cipher_welcome, iv_encrypt) assert (len(md5_indexi) == 32) # remove the last 16 byte for padding md5_token_idxi.append(md5_indexi[:16]) return md5_token_idxi
defdoin(unpadcipher, md5map, candidates, flag): if unpadcipher in md5map: lastbyte = md5map[unpadcipher] else: lastbyte = 0 if flag == 0: lastbyte ^= 0x80 newcandidates = [] for x in candidates: for c inrange(256): if MD5.new(x + chr(c)).digest()[-1] == chr(lastbyte): newcandidates.append(x + chr(c)) candidates = newcandidates print candidates return candidates
defmain(): bypassproof()
# result of encrypted Welcome!! iv_encrypt, cipher_welcome = recvmsg() log.info("cipher welcome is : " + cipher_welcome)
# get command not found cipher sendmsg(iv_encrypt, cipher_welcome) _, cipher_notfound = recvmsg()
# get encrypted(token[:i+1]),57 times md5_token_idx_list = get_md5_token_indexi(iv_encrypt, cipher_welcome, cipher_token) # get md5map for each unpadsize, 209-17 times # when upadsize>208, it will unpad ciphertoken # then we can reuse md5map = dict() for unpadsize inrange(17, 209): log.info("get unpad size {} cipher".format(unpadsize)) get_md5_iv = flipplain("token: ".ljust(16, '\x00'), "get-md5".ljust( 16, '\x00'), iv_encrypt) ## padding 16*11 bytes padding = 16 * 11 * "a" ## calculate the proper last byte number, only change the last byte ## set last_byte_iv = iv_encrypted[:15] | proper byte last_byte_iv = flipplain( pad("Welcome!!"), pad("Welcome!!")[:15] + chr(unpadsize), iv_encrypt) cipher = cipher_token + padding + last_byte_iv + cipher_welcome sendmsg(get_md5_iv, cipher) _, unpadcipher = recvmsg() md5map[unpadcipher] = unpadsize
# reuse encrypted(token[:i+1]) for i inrange(209, 256): target = md5_token_idx_list[56 - (i - 209)] md5map[target] = i
candidates = [""] # get the byte token[i], only 56 byte for i inrange(token_len - 7): log.info("get token[{}]".format(i)) get_md5_iv = flipplain("token: ".ljust(16, '\x00'), "get-md5".ljust( 16, '\x00'), iv_encrypt) ## padding 16*11 bytes padding = 16 * 11 * "a" cipher = cipher_token + padding + iv_encrypt + md5_token_idx_list[i] sendmsg(get_md5_iv, cipher) _, unpadcipher = recvmsg() # already in or md5[token[:i]][-1]='\x00' if unpadcipher in md5map or unpadcipher == cipher_notfound: candidates = doin(unpadcipher, md5map, candidates, 1) else: log.info("unpad size 1-16") # flip most significant bit of last byte to move it in a good range cipher = cipher[:-17] + strxor(cipher[-17], '\x80') + cipher[-16:] sendmsg(get_md5_iv, cipher) _, unpadcipher = recvmsg() if unpadcipher in md5map or unpadcipher == cipher_notfound: candidates = doin(unpadcipher, md5map, candidates, 0) else: log.info('oh my god,,,, it must be in...') exit() printlen(candidates) # padding 0x01 candidates = filter(lambda x: x[-1] == chr(0x01), candidates) # only 56 bytes candidates = [x[:-1] for x in candidates] printlen(candidates) assert (len(candidates[0]) == 56)
# check-token check_token_iv = flipplain( pad("Welcome!!"), pad("check-token"), iv_encrypt) sendmsg(check_token_iv, cipher_welcome) p.recvuntil("Give me the token!\n") p.sendline(base64.b64encode(candidates[0])) print p.recv()